Search Results:
Recommendation-engines-explained
posted on 17 Jun 2020 under category tutorial
Overview
Have you ever wondered how Netflix suggests movies to you based on the movies you have already watched? Or how does an e-commerce websites display options such as “Frequently Bought Together”?
They may look relatively simple options but behind the scenes, a complex statistical algorithm executes in order to predict these recommendations. Such systems are called Recommender Systems, Recommendation Systems, or Recommendation Engines.
A Recommender System is one of the most famous applications of Data science and Machine learning.
There are basically three types of recommender systems explained in this notebook -
- Demographic filtering (Simple Recommender)
- Content-Based Filtering
- Collaborative Filtering
Recommendation Engines
Three main categories of recommenders
- Knowledge Based Recommendations
- Collaborative Filtering Based Recommendations
- Model Based Collaborative Filtering
- Neighborhood Based Collaborative Filtering
- Content Based Recommendations
Often blended techniques of all three types are used in practice to provide the the best recommendation for a particular circumstance.
1. Knowledge based recommendation
Knowledge based recommendation: recommendation system in which knowledge about the item or user preferences are used to make a recommendation. Knowledge based recommendations frequently are implemented using filters, and are extremely common amongst luxury based goods. Often a rank based algorithm is provided along with knowledge based recommendations to bring the most popular items in particular categories to the user’s attention.
Rank based recommendation: recommendation system based on higest ratings, most purchases, most listened to, etc.
2. Collaborative filtering based recommendation - Neighborhood based
Collaborative filtering: a method of making recommendations based on the interactions between users and items.
Neighborhood based collaborative filtering is used to identify items or users that are “neighbors” with one another.
It is worth noting that two vectors could be similar by similarity metrics while being incredibly, incredibly different by distance metrics. Understanding your specific situation will assist in understanding whether your metric is appropriate.
2.1. Similarity based methods

-
Pearson’s correlation coefficient
Pearson’s correlation coefficient is a measure related to the strength and direction of a linear relationship.
-
Spearman’s correlation coefficient
Spearman’s correlation is what is known as a non-parametric statistic, which is a statistic whose distribution doesn’t depend on parameters. (Statistics that follow normal distributions or binomial distributions are examples of parametric statistics.) Frequently non-parametric statistics are based on the ranks of data rather than the original values collected.
-
Kendall’s Tau
Kendall’s tau is quite similar to Spearman’s correlation coefficient. Both of these measures are non-parametric measures of a relationship. Specifically both Spearman and Kendall’s coefficients are calculated based on ranking data and not the raw data.
Similar to both of the previous measures, Kendall’s Tau is always between -1 and 1, where -1 suggests a strong, negative relationship between two variables and 1 suggests a strong, positive relationship between two variables.
Though Spearman’s and Kendall’s measures are very similar, there are statistical advantages to choosing Kendall’s measure in that Kendall’s Tau has smaller variability when using larger sample sizes. However Spearman’s measure is more computationally efficient, as Kendall’s Tau is O(n^2) and Spearman’s correlation is O(nLog(n)).
2.2. Distance based methods

-
Euclidean Distance
-
Manhattan Distance
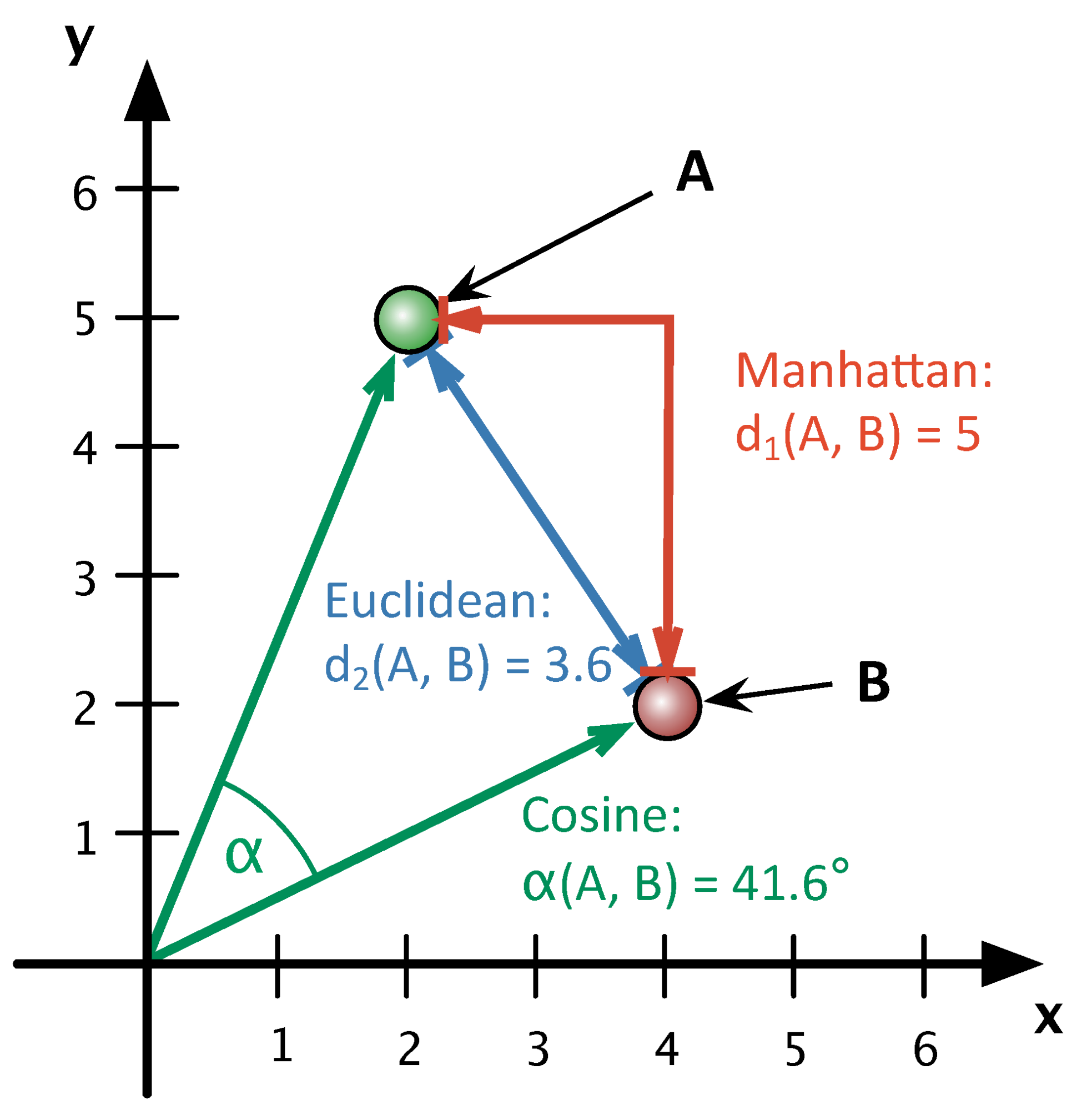
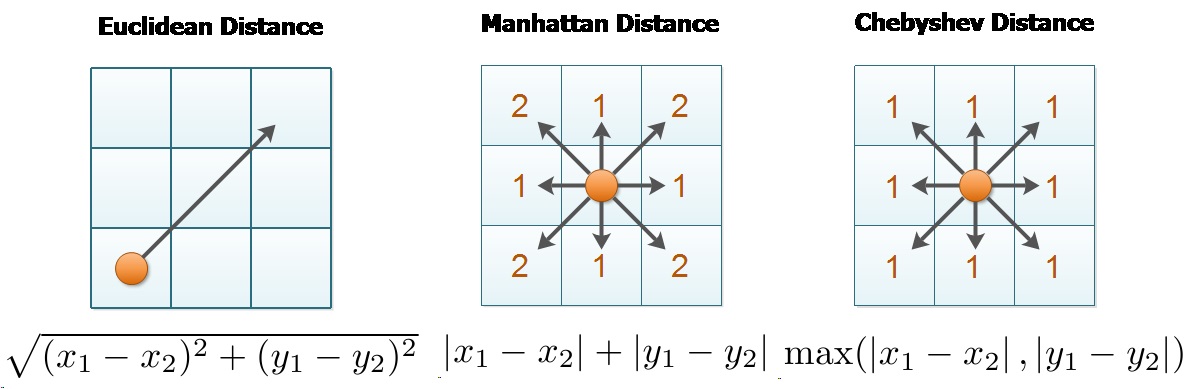
2.3. Making recommendations
-
User-based collaborative filtering
In this type of recommendation, users related to the user you would like to make recommendations for are used to create a recommendation.
-
A simple method
- Find movies of neighbors, remove movies that the user has already seen.
- Find movies whose ratings are high.
- Recommend movies to each user where both 1 and 2 above hold.
-
Other methods for making recommendations using collaborative filtering are based on weighting of the neighbors’ ratings based on the ‘closeness’ of the neighbors.
-
-
Item-based collaborative filtering
In this type of recommendation, first find the items that are most related to each other item (based on similar ratings). Then you can use the ratings of an individual on those similar items to understand if a user will like the new item.
3. Collaborative filtering based recommendation - Model based
3.1. Latent factors
-
Latent factors
When performing SVD, we create a matrix of users by items, with user ratings for each item scattered throughout the matrix. Using SVD on this matrix, we can find latent features related to the users and items.

Latent factor is a feature that isn't observed in the data, but can be inferred based on the relationships that occur.
-
Variability captured by latent features
The sigma matrix can actually tell us how much of the variability in the user-item matrix is captured by each latent feature. The total amount of variability to be explained is the sum of the squared diagonal elements. The amount of variability explained by the first componenet is the square of the first value in the diagonal. The amount of variability explained by the second componenet is the square of the second value in the diagonal.
3.2. The original Singular Value Decomposition (SVD)
- SVD algorithm

Consider reducing the number of latent features
- If we keep all k latent features it is likely that latent features with smaller values in the sigma matrix will explain variability that is probably due to noise and not signal.
- Furthermore, if we use these "noisey" latent features to assist in re-constructing the original user-movie matrix it will likely lead to worse ratings than if we only have latent features associated with signal.
-
SVD closed form solution
The most straightforward explanation of the closed form solution of SVD can be found at this MIT link. As put in the paper -
“Calculating the SVD consists of finding the eigenvalues and eigenvectors of AA’ and A’A. The eigenvectors of A’A make up the columns of V, the eigenvectors of AA’ make up the columns of U. Also, the singular values in Σ are square roots of eigenvalues from AA’ or A’A. The singular values are the diagonal entries of the Σ matrix and are arranged in descending order. The singular values are always real numbers. If the matrix A is a real matrix, then U and V are also real.”
-
(-) SVD in NumPy will not work when our matrix has missing values
3.3. FunkSVD
-
Gradient descent
To deal with missing values, use gradient descent to find the SVD matrices.


-
Pros and cons
- (+) Predict ratings for all user-item pairs
- (+) Regression metrics to measure how well predictions match actual videos
- (-) The cold start problem - use content-based or knowledge-based recommendations
3.4. The Cold Start Problem
The cold start problem is the problem that new users and new items to a platform don’t have any ratings. Because these users and items don’t have any ratings, it is impossible to use collaborative filtering methods to make recommendations.
Therefore, other methods such as rank-based and content-based recommenders are the only way to get started with making recommendations for these individuals.
3.5. Explicit vs. implicit ratings

When evaluating implicit ratings, use rank measure instead of RMSE.
4. Content Based Recommendation
Content based recommendation: recommendation system based on information about the users or items. This method of making recommendations is particularly useful when we do not have a lot of user-item connections available in our dataset.
-
Matrix multiplication
One of the fastest ways to find out how similar items are to one another (when our matrix isn’t totally sparse like it was in the earlier section) is by simply using matrix multiplication. An explanation is available here by 3blue1brown and another quick explanation is provided in the post here.
We can pull out the content related variables from the dataset. Then we can obtain a matrix of how similar movies are to one another by taking the dot product of this matrix with itself. Notice below that the dot product where our 1 values overlap gives a value of 2 indicating higher similarity. In the second dot product, the 1 values don’t match up. This leads to a dot product of 0 indicating lower similarity.

We can perform the dot product on a matrix of movies with content characteristics to provide a movie by movie matrix where each cell is an indication of how similar two movies are to one another. In the below image, you can see that movies 1 and 8 are most similar, movies 2 and 8 are most similar, and movies 3 and 9 are most similar for this subset of the data. The diagonal elements of the matrix will contain the similarity of a movie with itself, which will be the largest possible similarity (and will also be the number of 1's in the movie row within the orginal movie content matrix).

5. Applications
5.1. Example recommendation applications
- AirBnB uses embeddings in their recommendation
- Location-based recommemdation with collaborative filtering
- Deep learning use cases for recommendation systems
5.2. Choosing the rating scale
-
Some ideas to keep in min
- Do you need to ask questions of your user or can you collect data about their interactions with items?
- If you need to ask questions, how many do you ask?
- How do you word the questions?
- And finally, what type of scale should you use?
5.3. Business goals of recommendations
In general, recommendations are important because they are often central to driving revenue for a company. There are ultimately 4 goals to keep in mind when performing recommendations:
- Relevance - How relevant are the recommendations?
- Novelty - How surprising are the recommendations in general?
- Serendipity - How surprising are the relevant recommendations?
- Diversity - How dissimilar are the recommendations?
Want to support this project? Contribute.. 